Pour les non-initiés, l’informatique est un domaine assez magique où tout se résout plus ou moins tout seul. Quand ça ne fonctionne plus, c’est la catastrophe et on est perdu.
Certaines notions peuvent être un peu velues, mais le principe de fonctionnement est souvent assez simple. Il suffit de l’expliquer.
Parlons aujourd’hui du système de nom de domaine. C’est un système que tout le monde utilise au quotidien pour parcourir Internet et qui est très intéressant à explorer.
Les noms de domaine
Tous les services (site web, mail, jeux vidéo …) que vous utilisez sur Internet fonctionnent sur des serveurs. Pour avoir accès à un de ces services, il faut contacter le serveur correspondant et lui demander de livrer le service. Or le point de contact d’un serveur c’est son adresse IP.
On peut comparer ça à avoir la localisation (longitude et latitude) d’un endroit où l’on souhaite se rendre. Dans la théorie, on peut très bien se rendre n’importe où à partir de la longitude et latitude. Cependant, dans la réalité ce serait un enfer de se souvenir de chaque localisation. Et pour rendre ça viable, on utilise des adresses postales. Et bien pour l’informatique c’est pareil. Plutôt que de devoir se souvenir de chaque adresse IP, on a mis en place les noms de domaine.
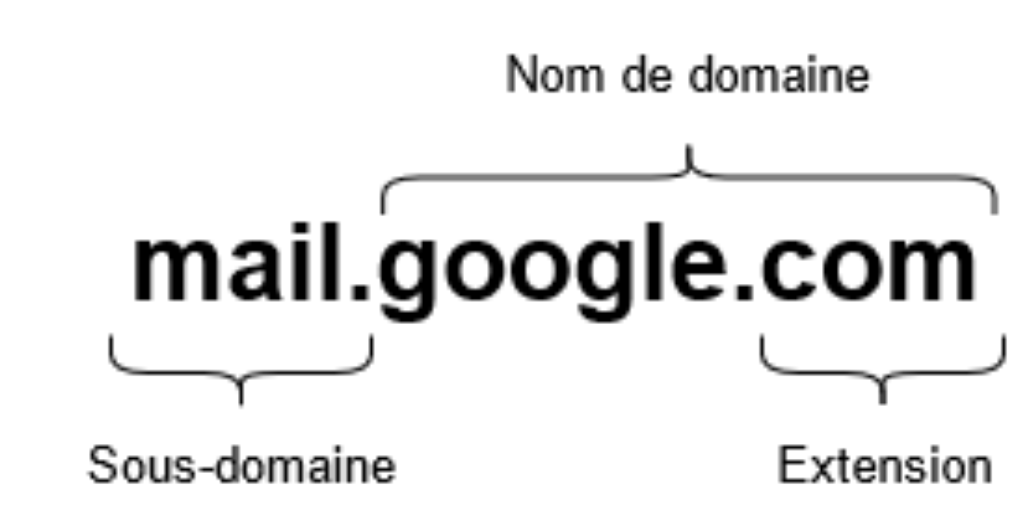
Un nom de domaine c’est donc (en partie) ce que vous voyez inscrit dans la barre d’adresse en haut de votre navigateur quand vous arrivez sur un site. C’est « google.com », « linkedin.com » ou « nameshield.com ». On peut constater que le nom de domaine se compose d’une chaîne de caractères, qui correspond généralement au nom d’une marque, d’un produit ou d’un service, et d’une extension (« fr », « com », « net », …).
Si on reprend notre comparaison avec une localisation, une fois arrivé à destination, on peut encore affiner notre objectif en choisissant à quel étage on veut se rendre. De même, pour les noms de domaine, on peut préciser notre demande en ajoutant un « étage » à notre nom de domaine, qu’on appelle sous-domaine : « mail.google.com ». Ici, on a « mail » qui est le sous-domaine et « google.com » qui est le nom de domaine. À partir de là, on peut mettre autant de sous-domaines qu’on le souhaite : « sous-sous-domaine.sous-domaine.domaine.net », mais c’est assez peu utilisé.
Les extensions
Comme on a pu le voir juste avant, la partie la plus à droite du nom de domaine est ce qu’on appelle une extension. On peut également l’appeler domaine de premier niveau (Top Level Domain ou TLD). Contrairement au reste du nom de domaine qui peut être composé de n’importe quels caractères alphanumériques, le domaine de premier niveau est choisi dans une liste préexistante. La liste de ces extensions se découpe en quatre types :
· Les ccTLD (country code Top Level Domain) : ce sont des extensions de deux lettres identifiant un pays ou territoire indépendant. Par exemple, on a le « fr » pour la France, le « us » pour les États-Unis, ou le « tv » pour le Tuvalu.
· Les gTLD (generic Top Level Domain) : ce sont des extensions historiques de trois lettres ou plus prévues pour des utilisations générales. On retrouve par exemple le fameux « com » qui a été créé pour une utilisation commerciale, le « gov » pour le gouvernement ou le « org » pour les organisations.
· Les new gTLD (new generic Top Level Domain) : devant la croissance d’Internet, l’autorité responsable des noms de domaine a décidé en 2012 d’introduire de nouvelles extensions. On retrouve le « xyz », le « bank » ou le « sport ».
· Les corpTLD (corporate Top Level Domain) : c’est en fait une sous-catégorie de new gTLD. Elle est réservée aux organisations souhaitant posséder leur propre extension. On y retrouve « hbo » ou « lego ».
Les serveurs de nom de domaine
Maintenant que l’on comprend un peu mieux à quoi correspond cette notion, on peut se demander de quelle manière notre ordinateur récupère l’adresse IP cachée derrière un nom de domaine. On appelle cette opération « résolution d’un nom de domaine ». En fait, en regardant la configuration réseau de notre ordinateur, on peut retrouver un champ DNS (Domain Name Server) où l’on indique une adresse IP d’un serveur de nom de domaine à qui on va faire les demandes de résolution à chaque fois qu’on utilise un nom de domaine. Ce serveur peut être appelé « résolveur DNS ». On peut noter que pour ce service, on est obligé de spécifier une adresse IP étant donné que si ce champ n’est pas configuré on n’a aucun moyen de résoudre un nom de domaine et donc on ne peut pas récupérer l’IP cachée derrière.
Vous vous dites surement « C’est bien beau, mais moi je l’ai jamais changé ce paramètre et pourtant mon ordinateur arrive quand même à résoudre les noms de domaine ! ». Et en fait, c’est très simple, parce que vous n’avez pas non plus configuré votre adresse IP sur votre ordinateur ; vous l’avez branché à votre box Internet et la magie s’est opérée. Et bien, c’est pareil, c’est votre router Internet qui a décidé quel DNS vous alliez utiliser. Donc par défaut vous utilisez le résolveur de votre fournisseur d’accès Internet.
Cependant, ce ne sont que des valeurs par défaut, et vous pouvez tout à fait choisir d’utiliser d’autres résolveurs DNS. Vous pouvez choisir d’utiliser ceux d’un autre fournisseur d’accès, mais aussi ceux d’un autre fournisseur de service.
Choisir son résolveur DNS est important, car de là dépend (en partie) la vitesse de livraison d’un service (si le serveur met du temps à vous renvoyer une IP, vous mettrez forcément plus de temps à récupérer la page web) ; mais aussi la confidentialité de vos données, car comme c’est lui qui résout tous vos noms de domaine, il connait tous les services que vous cherchez à joindre.
La résolution des noms de domaine
Un serveur de nom de domaine est donc une base de données de couple nom de domaine / adresse IP. Cependant, chaque serveur DNS ne contient pas la liste d’absolument tous les noms de domaine qui existent. Cela formerait des bases de données titanesques, ce serait un vrai calvaire à mettre à jour et ça serait des passoires en termes de sécurité.
Avant de rentrer dans le détail du cheminement d’une demande de résolution de nom de domaine, il va être indispensable, pour ne pas se perdre, de définir certaines notions relatives au DNS et notamment les différents types de serveurs DNS qui existent (parce que oui, il en existe différent, ce serait beaucoup trop simple sinon).
Notions importantes
ICANN : C’est l’Internet Corporation for Assigned Names and Numbers (Société pour l’attribution des noms de domaine et des numéros sur Internet). C’est une autorité de régulation d’Internet de droit privé et à but non lucratif. Elle a pour objectif l’administration des ressources numériques d’Internet telles que l’adressage IP et la gestion des domaines de premier niveau (vous vous souvenez, les TLDs).
Serveur récursif : Ce sont les serveurs que l’on imagine quand on parle de serveur DNS. Ce sont ceux qu’on configure dans le fameux champ DNS de notre configuration réseau et ce sont eux qui se débrouillent pour aller chercher l’adresse IP que l’on souhaite à partir d’un nom de domaine. Ces serveurs ont aussi une fonction de « cache », c’est-à-dire que lorsqu’on leur demande un nom de domaine qu’ils ne connaissent pas, ils font la recherche puis ils gardent l’information en mémoire au cas où on leur redemande. Il ne garde bien sûr cette information qu’un certain temps avant de devoir renouveler leur recherche (au cas où il y a eu une modification relative à ce nom de domaine).
Serveur Racine : Ce sont les treize serveurs gérés par l’ICANN qui ont pour objectif d’indiquer où se situent les serveurs responsables de chacun de domaine de premier niveau.
Serveur TLD : Ce sont les serveurs responsables de chacun des domaines de premier niveau. On retrouve un serveur pour le « fr », un serveur pour le « com », … (En vrai cela est plus complexe que « un serveur pour un TLD », mais l’idée globale est là). Et ces serveurs de noms de domaine répertorient le serveur faisant autorité pour chacun des noms de domaine qu’ils gèrent.
Serveur faisant autorité : Ce sont sur ces serveurs sur lesquels se retrouve l’information que l’on cherche, c’est-à-dire l’IP correspondant à un nom de domaine. Lorsqu’on modifie une information relative à un nom de domaine, c’est sur ces serveurs qu’elle est modifiée.
Le chemin de la résolution
Maintenant qu’on voit un peu plus clair dans les termes, on commence à distinguer un schéma qui se dessine ; schéma que je vais m’empresser de vous expliquer. D’après ce que je vous ai déjà dit, on sait que le serveur DNS configuré sur votre ordinateur (le serveur récursif) ne connait pas tous les noms de domaine qui existent, il doit donc trouver un moyen d’apprendre l’IP d’un nom de domaine qu’il ne connait pas. La recherche se fait de manière hiérarchique.
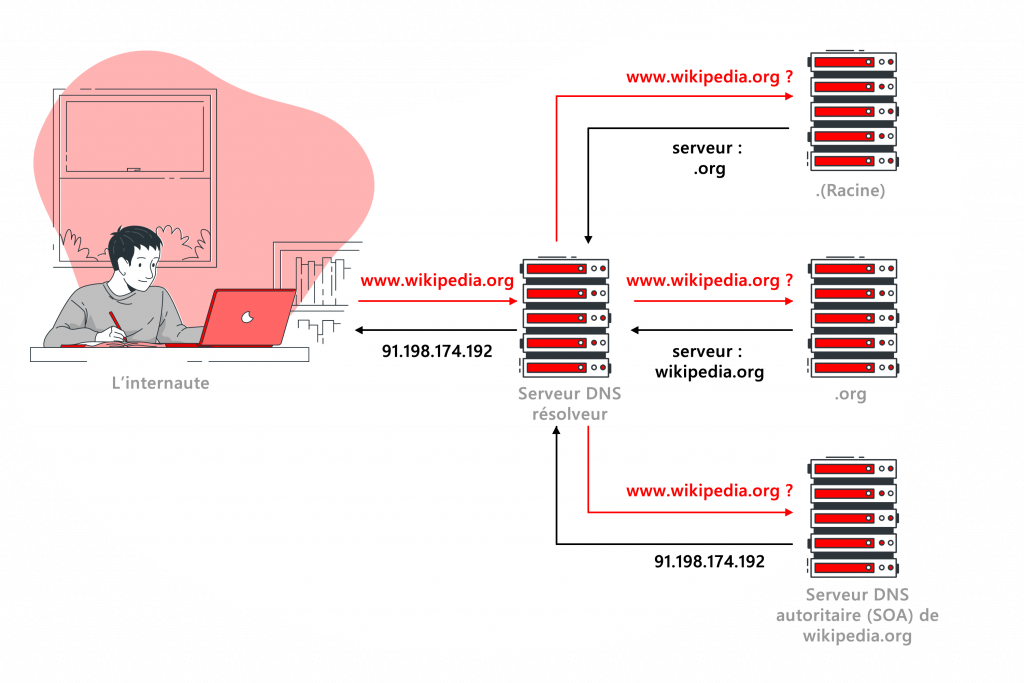
Pour comprendre comment ça marche, on va suivre le cheminement d’une demande de résolution d’un nom de domaine. Imaginons que l’on veut résoudre « www.nameshield.com ».
1. Notre ordinateur va commencer par faire une demande au serveur récursif qu’il a de configuré. On va dire qu’on est chez Orange, et on demande donc au serveur « 80.10.401.2 » : « Est-ce que tu connais l’adresse IP qui se trouve derrière le nom de domaine www.nameshield.com ? ». C’est une adresse que personne n’a jamais demandée au serveur DNS d’Orange (on va faire comme si c’était le cas) et du coup il ne connait pas la réponse.
2. Ne voulant pas rester dans l’ignorance, il va aller chercher cette information. Pour ce faire, il va aller interroger un des serveurs racines : « Dis-moi serveur racine, je dois résoudre www.nameshield.com, or je ne connais pas ce nom de domaine, peux-tu m’aider ? ». Ce à quoi le serveur racine va répondre « Hum… tu devrais demander à 192.134.4.1, c’est lui qui gère les .com ».
3. Le serveur récursif d’Orange va donc répéter sa question au serveur TLD du .com qui va lui répondre : « nameshield.com ? C’est un nom qui est enregistré chez Nameshield ça. Demande à 255.341.209.423 ».
4. Pour la troisième fois, notre serveur récursif pose la question au serveur faisant autorité qui lui répond « Bien sûr que je connais www.nameshield.com, c’est moi qui le gère ! Tu peux le trouver à 81.92.80.11 ».
5. Tout fier d’avoir enfin la réponse, notre serveur récursif nous la transmet et on peut alors contacter le serveur qui se cache derrière nameshield.com via son adresse IP.
Bien évidemment, on est en informatique et tous ces échanges ne prennent que quelques centièmes de secondes. Mais, on est toujours soucieux de gagner du temps, et donc le serveur récursif va garder l’information qu’on vient de lui demander en mémoire (au moins pendant quelques minutes), comme ça si on lui redemande 20 secondes plus tard, il ne va pas déranger les autres serveurs.
Conclusion
En dehors du milieu technique, on entend assez peu parler du système de nom de domaine (DNS), or c’est une notion qui mérite d’être connue, car c’est un vecteur important pour toute organisation. En effet, l’influence des noms de domaine se retrouve à tous les niveaux :
· Le nom de domaine représente une marque, un produit, une organisation, … il est donc important de le protéger. Il faut penser aux différentes possibilités lors de l’enregistrement pour pas que quelqu’un d’autre puisse le réserver et nuire à votre image.
· La configuration du serveur récursif que l’on va mettre en place sur notre machine va jouer sur la vitesse de votre Internet, mais aussi la confidentialité de vos données.
· La disponibilité de tout Internet dépend de la disponibilité du système de nom de domaine. Si les serveurs racine, TLD ou faisant autorité tombent, on n’a plus accès à aucun service.
Tout ça pour dire, que le DNS, c’est complexe, mais c’est crucial !
Source de l’image : storyset.com